In the world of web applications, not everything should be done in real time.
Imagine a user submits a form that sends a welcome email, updates a CRM, and posts data to a third-party service. If all of that happens synchronously—right as the form is submitted—the user has to wait for every one of those tasks to finish.
That means long response times, bad user experience, and potentially, timeouts.
That’s where background job processing comes in. It allows developers to move such time-consuming operations out of the request-response cycle, making the application more responsive and resilient.
With background jobs, we get performance, reliability, and the ability to scale the application better without burning out the main application thread.
Rails has long recognized this need, and over the years, the ecosystem around background jobs has evolved significantly. But Rails is not the only one.
Every serious backend framework or language—from Python’s Celery to PHP’s Laravel Queues—has a way to handle asynchronous operations.
Each one approaches the problem differently, depending on the ecosystem’s strength and philosophy.
Understanding Background Processing and Its Importance
At the heart of every modern web application is the need to respond quickly to user actions.
Whether a user is signing up, placing an order, uploading files, or triggering notifications, they expect speed.
However, not all tasks can—or should—be completed instantly.
Some actions, such as sending emails, generating PDFs, uploading large files to cloud storage, or syncing data with external APIs, can take several seconds or even minutes to complete. If these operations are executed during the user’s request-response cycle, they cause noticeable delays.
Worse, they might cause the app to timeout or crash under load.
This is where background processing becomes crucial.
The idea is simple: offload time-consuming or non-critical tasks to a separate process that can run asynchronously in the background.
That way, the main application can quickly return a response to the user while the heavy lifting continues behind the scenes.
Think of it like placing an order at a restaurant—you order at the counter, get your receipt, and wait at your table while the kitchen prepares the meal.
You’re not stuck at the counter watching every step of the cooking process.
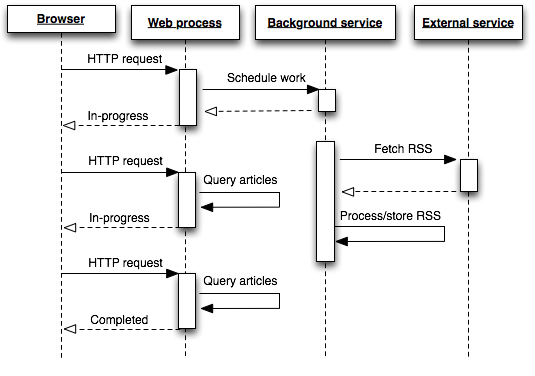
From a technical point of view, background processing typically involves job queues and worker processes.
A job represents a unit of work to be done—like sending an email or processing a video.
These jobs are pushed onto a queue. Worker processes constantly monitor this queue and pick up jobs to execute them. This separation allows your application to be more responsive, resilient to failure, and easier to scale. You can add more workers as your load increases or pause them for maintenance without impacting your main application.
Let’s look at a very simple conceptual example of how this works in Ruby on Rails:
#app/jobs/welcome_email_job.rb
class WelcomeEmailJob < ApplicationJob
queue_as :default
def perform(user_id)
user = User.find(user_id)
UserMailer.welcome_email(user).deliver_now
end
end
And in your controller:
def create
@user = User.create(user_params)
WelcomeEmailJob.perform_later(@user.id)
redirect_to root_path, notice: "Signed up successfully!"
end
In this example, instead of sending the welcome email during the signup process, we defer that task to a background job using perform_later. This immediately returns control back to the user, allowing the app to respond without delay. The job will be picked up by a worker and executed separately.
The benefits are not just limited to speed. Background jobs also help with:
- Scalability: Workers can be distributed across machines.
- Reliability: Failed jobs can be retried without affecting users.
- Maintainability: Separating logic makes the code cleaner and more testable.
- Fault tolerance: If a job fails, it doesn't crash your web server.
Without background processing, building fast and scalable web applications becomes nearly impossible. Especially in high-traffic environments or systems that depend on external integrations, having robust job processing in the background is not optional—it’s a fundamental necessity.